
Die heute in der Praxis verwendete schwache KI ist ein selbstlernendes System. Der Lernprozess erfolgt anhand von Beispielen, die der KI in Form von Daten während der Trainingsphase zur Verfügung gestellt werden. Während der anschließenden Anwendungsphase lernt eine schwache KI nicht mehr dazu. Die heutige KI-Technologie ist mittlerweile für die Produktion geeignet. Neuronale Netzwerke können zuverlässig trainiert und ausgeführt werden, C++ und Netzwerkoptimierung ermöglichen den zuverlässigen Betrieb und die Prozessintegration. Eine breite Palette verfügbarer Hardware, von Embedded-Systemen bis hin zu Highend-Rechenzentrumslösungen, ermöglicht den Einsatz von KI-Lösungen in einer Vielzahl von Anwendungsfällen.
Bessere Ergebnisse mit weniger Daten?
Zur Lösung eines allgemeinen Erkennungsproblems mit Hilfe von Deep Learning empfehlen wir je nach Komplexität 1.000 bis 10.000 Datensätze pro Klasse. Auch wenn alle anderen Voraussetzungen erfüllt sind, bleibt die erforderliche Menge an Daten das Haupthindernis für eine flächendeckende Einführung von KI. Zur Lösung des Datenproblems sehen wir aktuell drei unterschiedliche Ansätze: a) Sparse Modelling, b) Transfer Learning und c) Deep Learning mit automatisierter Datengewinnung. Mit den ersten beiden Ansätzen versucht man die Anforderungen an die Menge der zum Training einer KI verwendeten Daten deutlich zu reduzieren. Der systematische Nachteil gegenüber Deep Learning mit seinen hohen Datenanforderungen liegt allerdings im Informationsgehalt, bzw. der Entropie der Daten. Je geringer die verwendete Datenmenge zum Training einer KI, desto größer die Gefahr, dass eine KI Scheinmerkmale lernt. Diese beschreiben die Objekte zwar innerhalb der zum Training verwendeten Daten, sind jedoch nicht auf die Realität bzw. Gesamtheit übertragbar. Alternativ lassen sich die benötigten Daten für das Training einer KI mit hochautomatischen Verfahren gewinnen. Damit lassen sich umfangreiche Datensätze mit einem hohen Informationsgehalt erstellen, mit denen sich – unabhängig von der KI-Technologie – grundsätzlich bessere Ergebnisse erzielen lassen.
Prototypisches KI-Projekt
Im folgenden betrachten wir die Einführung einer plattformbasierten Deep Learning Lösung in eine Produktion. Dabei gehen wir davon aus, dass zu Projektbeginn keine Daten verfügbar sind:
- Erstabschätzung der Machbarkeit: In Bezug auf die Machbarkeit bietet sich folgende Abschätzung an: Ist das Objekt bzw. die gewünschte Eigenschaft in unter einer Sekunde vom Menschen erkennbar, so ist in der Regel eine zuverlässige Erkennung mit Hilfe von Deep Learning möglich.
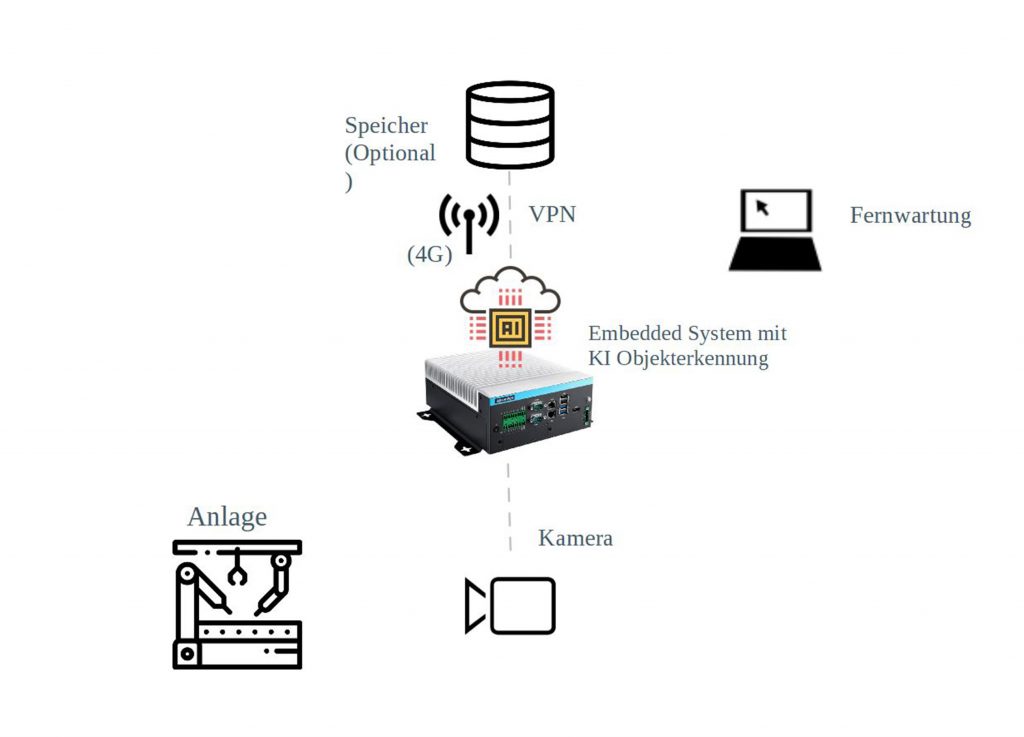
- Konzeptphase: Da beim Einsatz von Kameras große Datenmengen anfallen, empfiehlt sich der Einsatz von Computersystemen in der Nähe der Kamera (Edge-Computing). Neben den klassischen PC-Systemen (mit GPU) können auch lüfterlose Embedded-Systeme mit geringen Strombedarf zum Einsatz kommen. Darüber hinaus wird festgelegt, welche Objekte bzw. Eigenschaften erkannt werden sollen und in einem Katalog erfasst. Wichtig: Für das Training der KI mit Deep Learning werden erhebliche Datenmengen benötigt. Diese können auf dem Computersystem oder einem zusätzlichen Netzwerklaufwerk zwischengespeichert werden. Der Zugriff auf diese Daten erfolgt idealerweise über ein virtuelles privates Netzwerk. Aus Sicherheitsgründen kann der Zugriff statt über das interne Netzwerk auch über 4G bzw. das Training auf einem sogenannten GPU-Server vor Ort erfolgen.
- Machbarkeitsanalyse: Um die Machbarkeit nachzuweisen, wird eine Anzahl von Daten erfasst und meist manuell für das Training der KI aufbereitet. Mit einem Aufwand von normalerweise fünf bis zehn Tagen dauert diese Phase je nach Aufwand und Komplexität eine bis vier Wochen. Deep Learning Lösungen skalieren beinahe unbegrenzt mit zusätzlichen Daten. Das Projektrisiko von Deep Learning Lösungen ist daher deutlich geringer, da zur Verbesserung der Erkennung meist nur zusätzliche Daten hinzugefügt werden müssen. Der Projekterfolg lässt sich nach dem erfolgreichen Abschluss der Machbarkeitsanalyse oft schon gut abschätzen.
- Durchführung: Die Durchführung ist ein iterativer Prozess basierend auf (hoch)automatisierter Datenerfassung und -gewinnung. Dabei kommt bereits durchgängig KI zum Einsatz. Zum einen wird eine KI auf dem Computersystem verwendet um potentiell relevante Daten für das Training zu identifizieren. Danach werden in zyklischen Intervallen die gewonnen Daten geladen und in einem hochautomatischen Prozess für das Training der KI vorbereitet (gelabelt). Der Aufwand für rund 100.000 Bilder liegt dabei im Durchschnitt bei fünf bis zehn Tagen. Wie oft dieser Schritt durchgeführt werden muss, hängt vor allen von der Anzahl der Objektklassen sowie der Verteilung der Daten ab. Abschließend wir eine KI trainiert und gegen einen separaten Datensatz getestet.
- Integration: Auf C++ basierende Plattformen lassen sich in der Regel gut in eine spezifische Umgebung integrieren. Der Aufwand ist dabei von den jeweiligen Anforderungen abhängig.
- Gesamtkosten: Dank einer bereits weit entwickelten KI-Plattform und hochautomatisierten Prozessen für die Datengewinnung lassen sich Projektkosten und -risiko deutlich reduzieren. Die Gesamtkosten einer individuellen Lösung für die Objekterkennung von einfacher bis mittlerer Komplexität liegen in der Regel im unteren bis mittleren fünfstelligen Bereich. Abhängig von der Verteilung der Daten kann dabei Projektdauer und -aufwand deutlich voneinander abweichen. Die Kosten für die Hardware liegen normalerweise im vierstelligen Bereich.











