Bevor KI eine breite Akzeptanz in Unternehmen und Gesellschaft erfährt, müssen einige Herausforderungen gelöst werden. Doch letztendlich wird die Vertrauenswürdigkeit der KI-Technologie als Schlüssel für deren Erfolg gesehen. Aber wie kann diese aufgebaut werden? Ausgehend von der Definition, dass Vertrauen als die subjektive Überzeugung von der Richtigkeit einer Aussage und von Handlungen zu verstehen ist, kann ein KI-System generell als vertrauenswürdig eingestuft werden, wenn es sich für den vorgesehenen Zweck immer wie erwartet verhält. Daraus lässt sich folgern, dass Vertrauenswürdigkeit nachweisbar ist. In Bezug auf KI sind somit grundlegend folgende Faktoren relevant, die im Weiteren erläutert werden:
- Die Eingangsdaten der KI müssen eine hohe Qualität für den Anwendungsfall aufweisen.
- Die IT-Anwendung und das KI-System sind von KI- und Anwendungsexperten konzipiert sowie manipulationssicher und vertrauenswürdig umgesetzt.
- Ergebnisse nachzuvollziehen wird ermöglicht.
- Bei der Entwicklung und Anwendung werden jeweils ethische Grundsätze eingehalten.
Qualität der Eingangsdaten
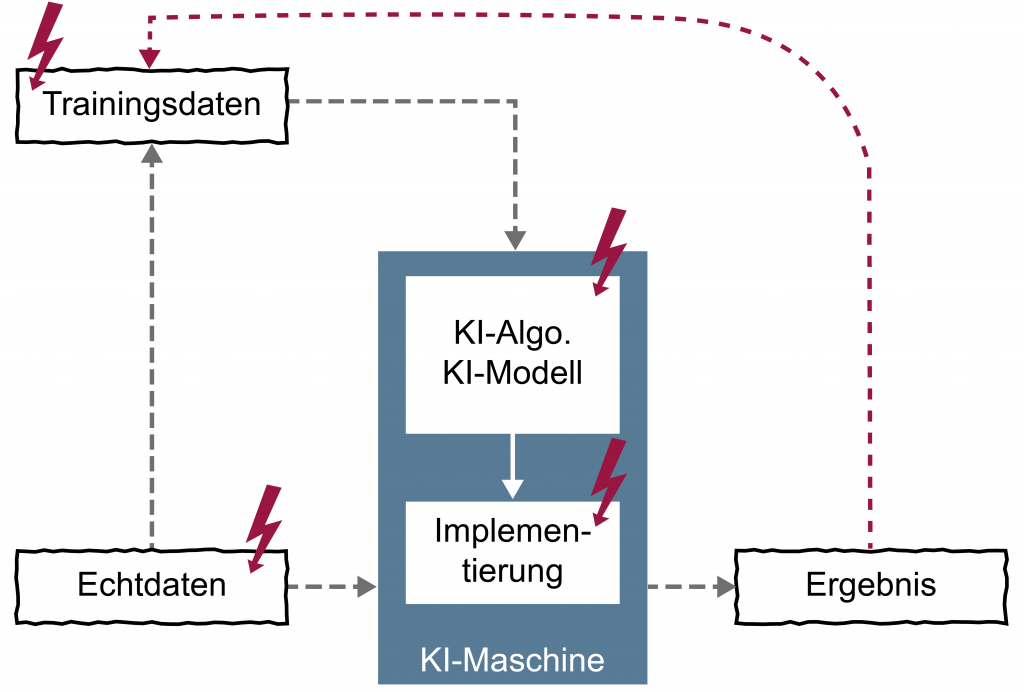
Grundsätzlich basiert die Entwicklung und im Weiteren der Einsatz von KI-basierten Anwendungen auf Daten – etwa für das Trainieren des KI-Algorithmus sowie auch für dessen Nutzung. Unter dieser Prämisse ist eine differenzierte Analyse der Daten – bezüglich ihres Werts respektive ihrer Aussagekraft im Sinne der Aufgabenstellung – beider Kategorien ein essentieller erster Schritt zur Sicherstellung der Vertrauenswürdigkeit von KI-basierten Anwendungen. Denn aufgrund ihrer hohen Relevanz entscheidet deren Auswahl und Qualität maßgeblich über das Ergebnis. Aus diesem Grund sollte es obligatorisch sein, entsprechend Positionen im Unternehmen zu konstituieren, die für das Modell der Datengewinnung und -nutzung zuständig sowie für die Kontrolle der ordnungsgemäßen Umsetzung verantwortlich sind. Gemäß vorgegebener Kriterien lässt sich der Standard der Datenqualität für KI-Systeme sowohl etablieren als auch validieren. Im Einzelnen sind dabei unter anderem Vollständigkeit, Repräsentativität, Nachvollziehbarkeit, Aktualität und Korrektheit zu berücksichtigen.
Vollständigkeit der Daten
Die Grundvoraussetzung für Vollständigkeit ist, dass ein Datensatz alle notwendigen Attribute und Inhalte enthält. Kann die Vollständigkeit der darin inkludierten Daten nicht garantiert werden, entsteht daraus potentiell das Problem von irreführenden Tendenzen, was letztendlich zu falschen oder diskriminierenden Ergebnissen führt. Dieses Phänomen tritt unter anderem bei Predictive Policing-Systemen auf: Wenn beispielsweise die Datenerhebung zu Kriminalitätsdelikten von vorneherein massiv in definierten Stadtvierteln stattfindet und dies im Kontext mit bestimmten Merkmalen wie Herkunft und Alter geschieht, ergibt sich daraus im Laufe der Zeit, dass dort bestimmte Bevölkerungsgruppen stärker überwacht und durch die häufiger durchgeführten Kontrollen letztendlich per se kriminalisiert werden. Der (vermeintliche) Tatbestand kann jedoch unter Umständen lediglich darauf basieren, dass entsprechende Vergleichswerte unter Berücksichtigung der gleichen Merkmalen aus anderen Stadtvierteln nicht im adäquaten Maße erhoben wurden. Vollständigkeit bedeutet somit keinesfalls, wahllos möglichst viele Daten zu erfassen – entscheidend ist die Auswahl.
Repräsentativität der Daten
Die Repräsentativität zeichnet sich dadurch aus, dass die Daten eine tatsächliche Grundgesamtheit und somit entsprechend die Realität abbilden, die stellvertretend im Sinne der Aufgabenstellung ist. Sind die Daten nicht repräsentativ, hat dies zur Folge, dass daraus ein Bias resultiert. Dieses Phänomen tritt beispielsweise im Recruiting von Führungskräften auf, wenn hier größtenteils Daten aus der Vergangenheit berücksichtigt werden und in dieser Zeit überwiegend Männer in Führungspositionen waren. Mit der Konsequenz, dass die KI-basierte Anwendung daraus folgern müsste, dass Männer für diese Positionen qualifizierter seien. Ergebnisse wie diese zeigen, dass durch KI-Systeme nicht zwangsläufig Objektivität erreichbar ist.